Introduction
I regularly use Sudokus as a Hello World use case for what you can use Google OR Tools for. I decided to take it a few steps further to see if I could create an end-to-end solution for solving a Sudoku in the quickest way possible. I wanted to expand my OR Tools Sudoku solver into an AI pipeline, where the OR Tools implementation is one part of a string of events to solve a Sudoku pretty much instantly.
I'm by no means a trailblazer here. If you google "Sudoku solver" or similar, you'll see loads of results that are all pretty much doing the same thing. In fact, the code for parts of the problem are (shamelessley plagiarised) based upon this github repo. I would also recommend watching this youtube video where the author goes into detail about how he approached this problem, which I found really interesting.
You can find the code for my implementation here, feel free to try out the app for yourself as well here!
Here's a quick demo in its current state:
Breaking down the problem
I decided to break my problem down into three stages:
- Sudoku detection: given an image, return at most 1 Sudoku present in the image.
- Digit OCR: sub-divide the Soduku into the 81 cells that make up the 9x9 grid, and run OCR to find what digits are already there.
- Send the unsolved Sudoku to Google OR Tools and show the solution to the user (ideally with a sexy CSS animation).
Breaking it down like this allowed me to solve each part in isolation, using the most appropriate solution for each stage. Here's a visual breakdown of what I'm doing in each step:
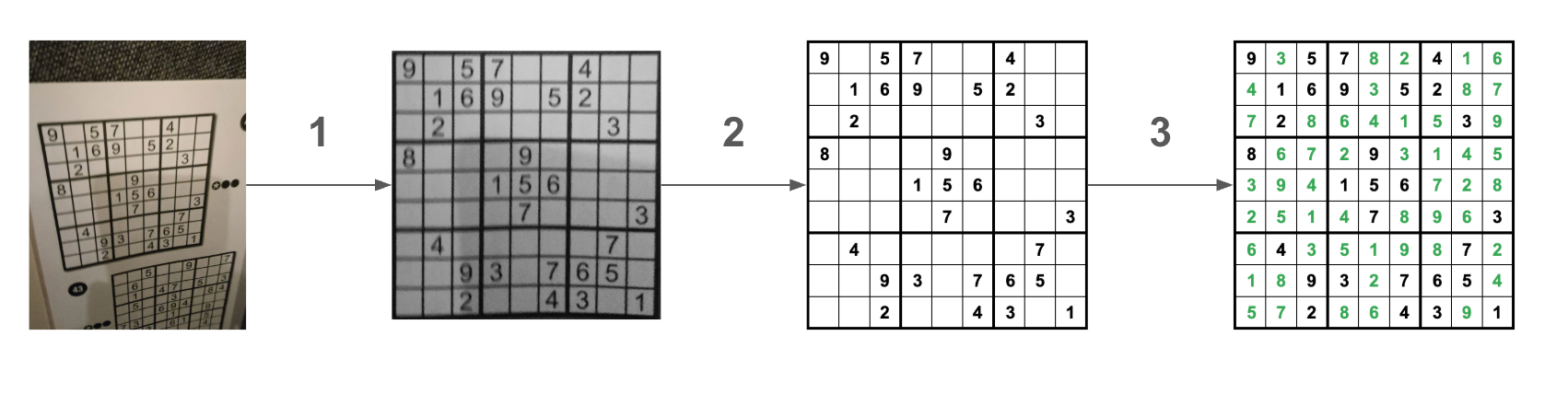
Sudoku detection
At the end of this stage, the aim is to have a region representing a sudoku. I could have used many different approaches here, and it might surprise you to learn that I didn't even go with an AI-based solution for this stage. I tried to train my own object detection model, but it performed really poorly. As obvious as it seems in retrospect, the only thing any two sudoku puzzles have in common is the 9x9 grid containing the digits for that specific puzzle. I wouldn't describe myself as an expert in training object detection models so perhaps I could have persevered here, but the amount of false-positives I got from my model made me crawl back to the drawing board. This was a nice refresher for me that AI isn't always just magic, and sometimes pulling your sleeves up and doing it manually is the best (and possibly most rewarding) approach.
That being said, a manual approach has its drawbacks as well. For example, my approach doesn't handle sudokus in dark theme, nor would it be able to find a sudoku if its border happened to be dotted or dashed. It works brilliantly on my £1.99 puzzle book I bought from Asda, and that's good enough for me.
Now, into the approach. Put simply, we need to find the biggest square in a given image. This doesn't need to be a perfect square, as it would be practically impossible for a human to take a photo of a sudoku such that the area it takes up on the image is perfectly square. We'll therefore add tolerances to sanity check what the application thinks might be a square rather than checking that the height = width exactly.
To find our square, we'll iterate through the pixels on the image. For each pixel, we'll return all the other pixels which are "connected" to it i.e there exists a path between the pixels such that all pixels along the path are the same colour (the same hex code). Our square is the largest connected region that lies within the tolerances mentioned above. This presents a problem in that, to the naked eye, two pixels that look the same colour are very likely to have a different hex code. We therefore need to apply a process called adaptive thresholding, which is where we reduce our image into one such that each pixel is one of two colours: white or black. This polarisation of pixels allows us to find a collection of points of all the same colour on the thresholded image that are most likely to contain a sudoku. Here's what an image of a sudoku looks like when adaptive thresholding is applied:

Looking at this image, it's easy to see what the largest number of white connected pixels would be, and that's exactly what our program was able to find.
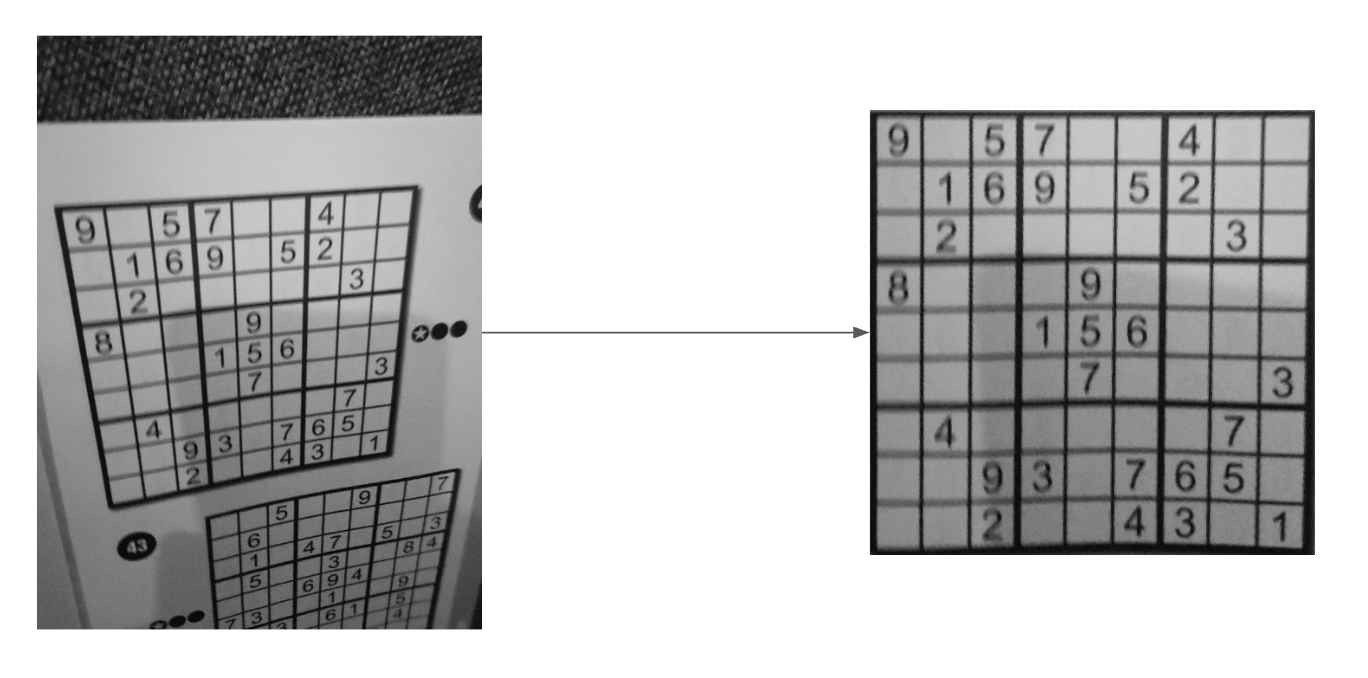
At this point, we have a region containing a sudoku. However, there's a need for this region to be square so we can easily divide it into smaller squares where we can expect to find a digit. If we were to subdivide this image now, it would look for digits in the wrong place. Here's an image of me sub-dividing this regions manually to illustrate that point:
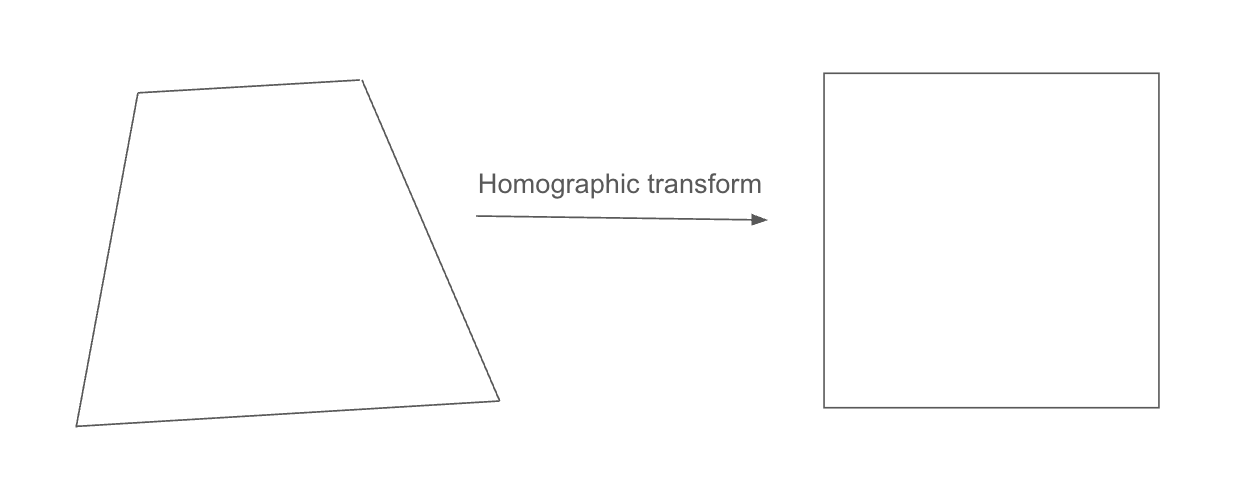
We need to transform our image into a square. Specifically, this needs to be a homographic transform. Once we have our transform, we can construct a new image that's perfectly square and ready to sub-divide.
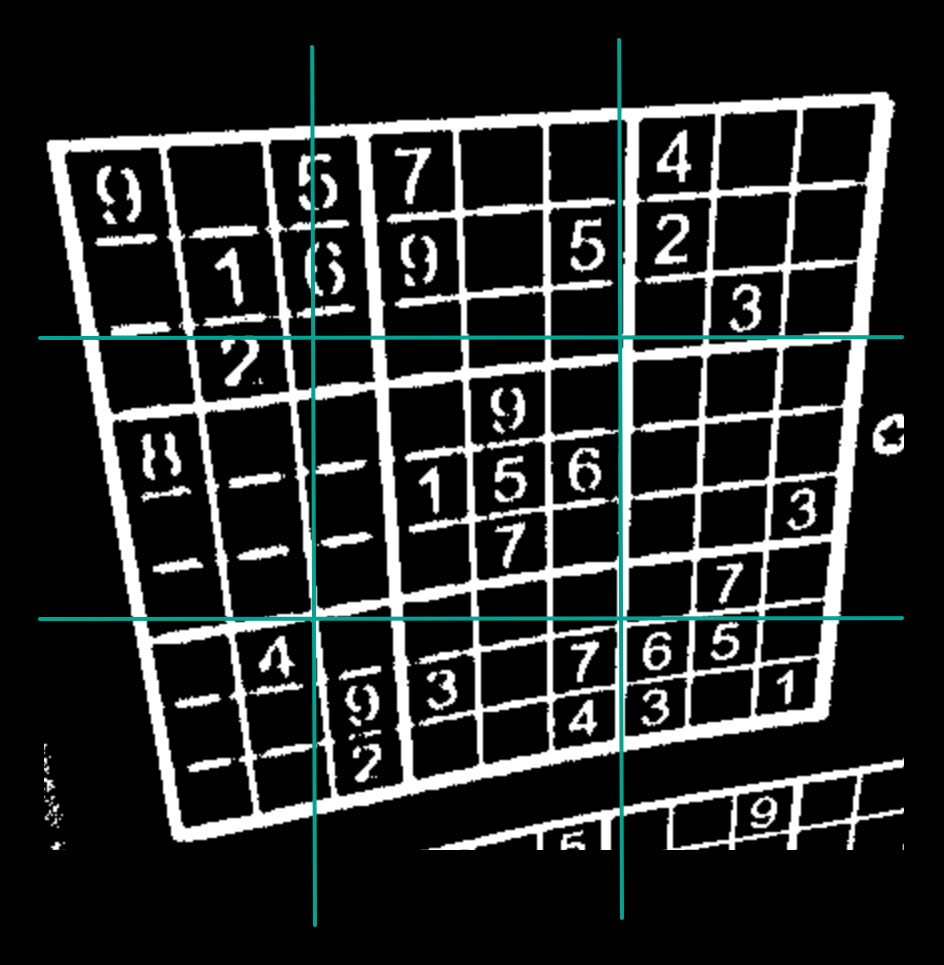
The first step is to find what we think are the corners of our sudoku. To do this, for each corner, we find the closes point to it using manhattan distance. I added a bit of padding to the region to illustrate how manhattan distance works:

We need to map these four points onto the corners of a square. This is where we can get pretty deep into the maths of it all, but for brevity you can determine the homographic transform using this guide (note, I used mathjs for the matrix operations). Once we've got the transform we can show our sudoku as a square, ready for further processing.
Digit OCR
Now we've got a Sudoku, we need to be able to say what existing digits are there so we can solve the remainder of the puzzle in stage 3. Firstly, we need to find which cells contain a digit so that we can process the sub-image and determine what digit is in the cell. For this stage, I went with a pre-trained tensorflow model.
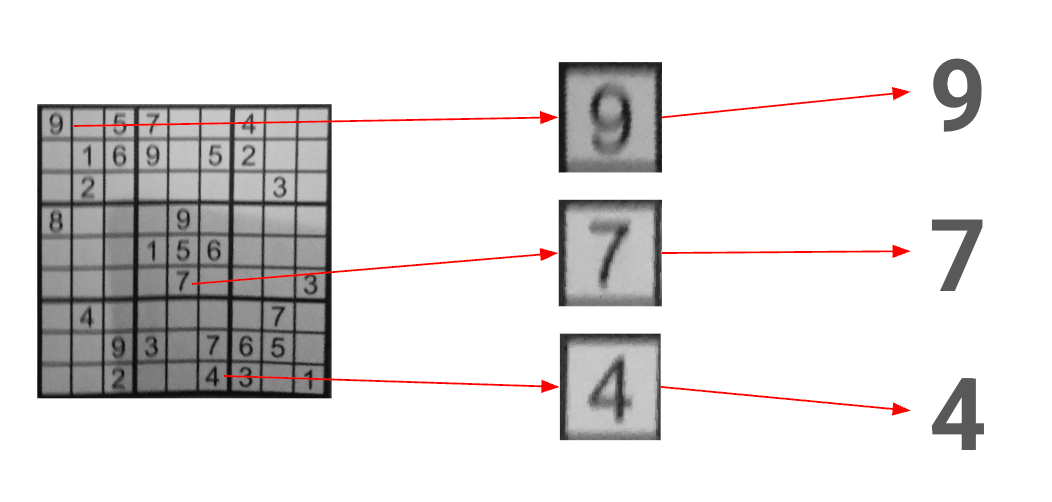
Once sub-divided, we can re-use the code in stage 1 to return the largest connected region of each cell. We can again use tolerances to ensure we flag a cell as containing a digit if the found region is of a large enough size (again, no AI yet).
At this point, all the AI can take place in the browser thanks to the magic of tensorflowjs. Now, this model isn't mine, it was made by the same person who I linked in the introduction of the post. One thing that surprised me was how lightweight an AI model can be. So lightweight infact that you can even bundle it in your application and use it directly in the browser, and that's exactly what I did:
If you didn't know already, you can find a heap of pre-trained models online in TensorFlow Hub. I tried a few models which matched the search term "digit recogniser", but this one worked the best.
Solve the Sudoku
Right, I've used the AI buzzword now - I can get onto my favourite bit: OR Tools. To save me re-introducing it every post, I give a summary of what it is here. Because there is always exactly one solution to a Sudoku we can't brand this as an optimisation problem, but it's a great example of finding the single feasible solution from a high number of infeasible ones.
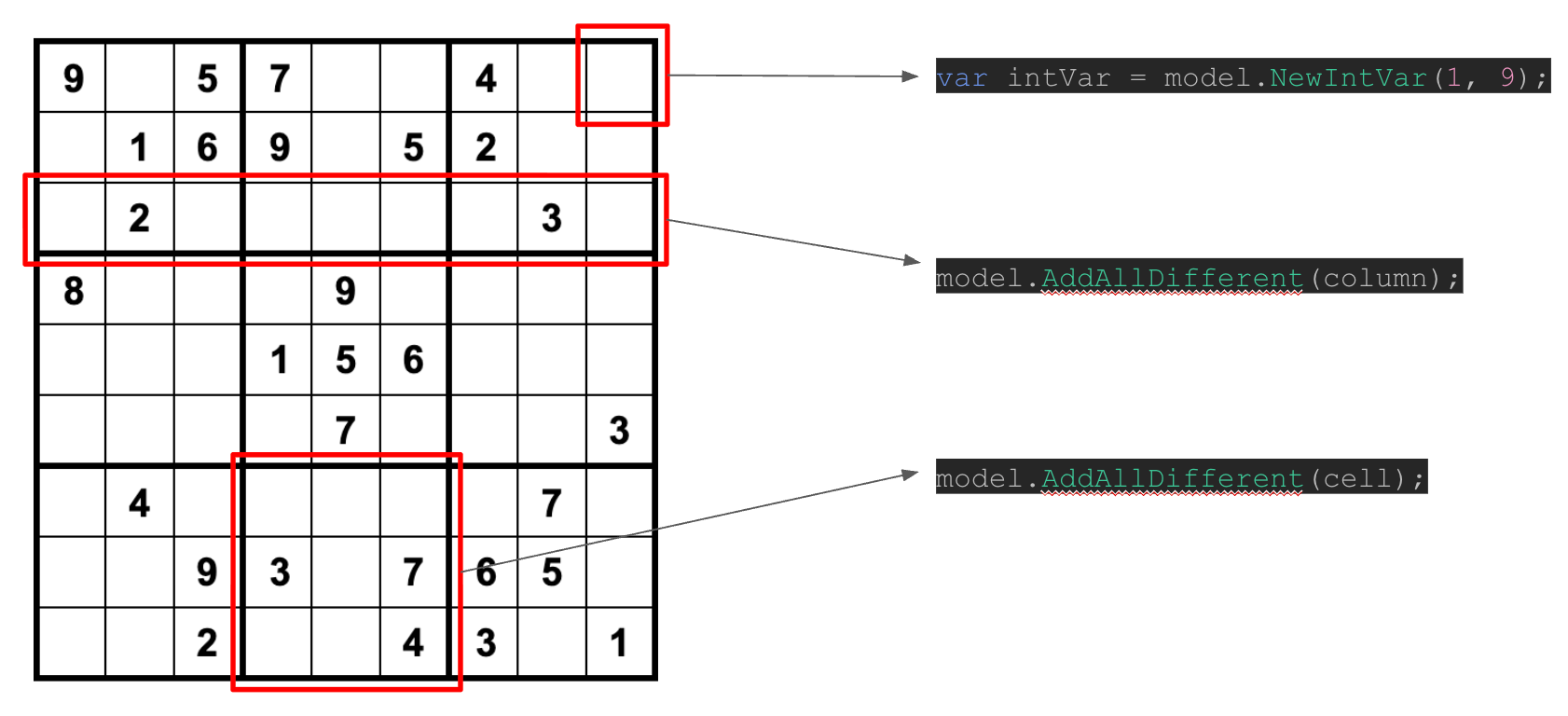
Now we have a digital representation of a sudoku, I can create a variable for each blank cell with possible values of all integers between 1 to 9, and with just a few more lines of code, let OR Tools do the rest.
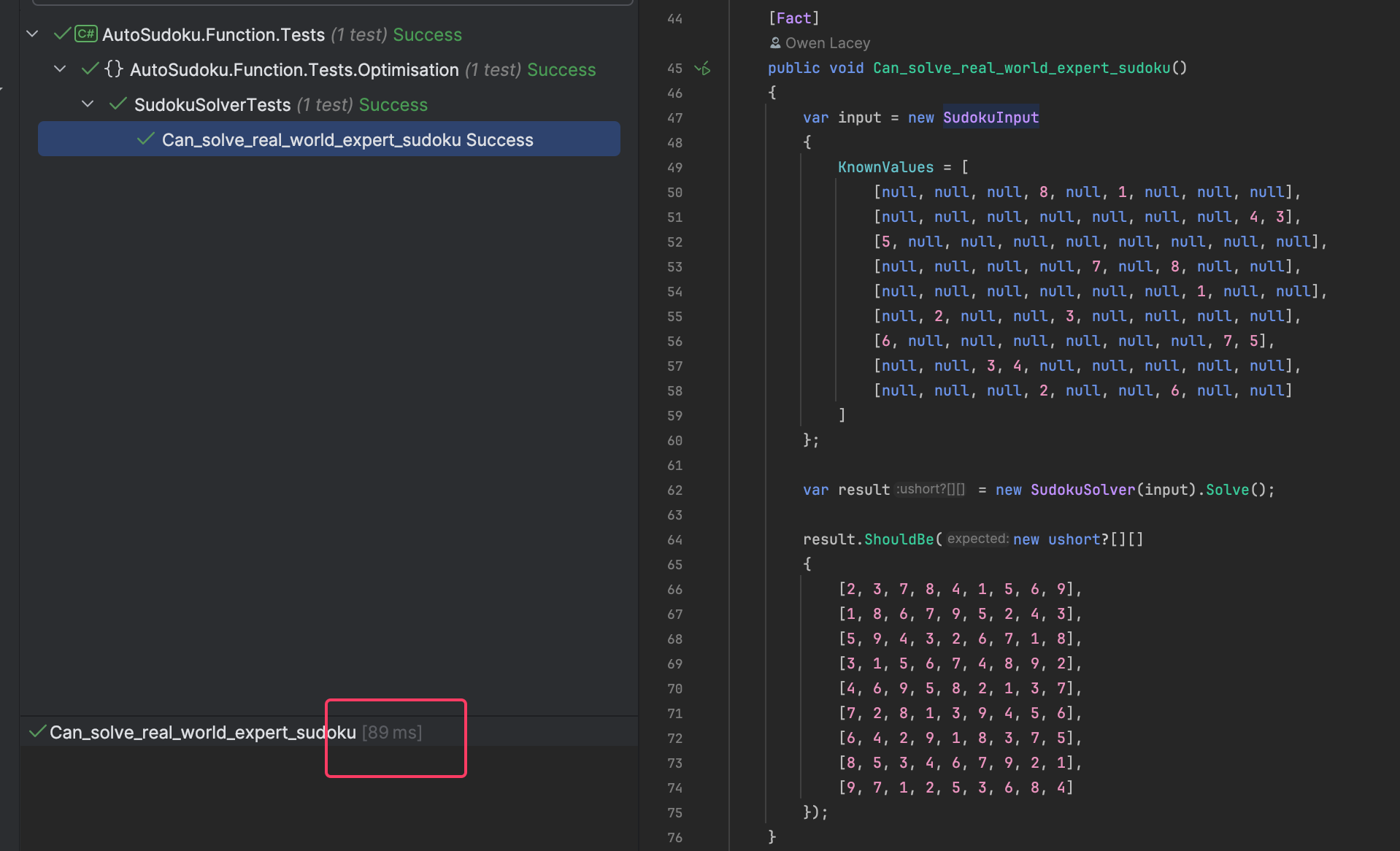
Circling back to what I said at the top of this post - this thing needs to be fast. Here's how quick it is for an expert level sudoku:
Wrapping up
What started as a simple "Hello World" demo with OR Tools turned into a really rewarding journey in a completely new area for me in image processing techniques. My main takeaway is that just because you can use AI to solve a problem doesn't mean you should - manual methods still have their place, especially when they just work.
It’s definitely not perfect, but it was great fun to build—and I learned loads doing it. If you want to try it out yourself or poke around the code, you can find all the links you need at the top. Thanks for reading!